
Introduction to PV Factory
PV Factory is a cloud-based simulation of how screen-printed silicon solar cells are manufactured. Throughout these tutorials you will learn the science and technology associated with each processing step and then you will be required to optimise the processing steps. For all tutorials, unless specified otherwise you will use the UNSW Screen Print Production Line in “PV Factory”.
The size of the datasets generated during PV manufacturing is large. Just consider 3,000 cells being produced per hour. That is 72,000 cells a day! In PV Factory you will fabricate much smaller batches of cells (10 or 20 cells per batch), however, the principles that you will learn will be similar. In the tutorials you will use Microsoft Excel to perform the required statistical analyses but you may wish to explore the use of other statistical packages (e.g., XLSTAT or Minitab).
Many of the processes that you will optimise using PV Factory depend on many different (correlated) variables and so they are difficult to optimise. The problem you are frequently faced with is determining which variable is the most critical to optimise. I.e., changing what parameter is going to give you the greatest improvement in performance. This problem is made even more difficult because many of the steps in the production process also depend on other processes. In this tutorial you will be introduced to PV Factory and learn some basic statistics on sampling and how to design multiple and single factor experiments that will be useful in your analysis in the subsequent tutorials.
Learning Objectives
- Determine which graphical models are appropriate for what data
- Understand the difference between samples and populations and be able to compute sample means and standard deviations for batches of simulated data
- Calculate confidence intervals for datasets where the true mean and standard deviation are not known
- Report the results of measurements to the correct number of significant figures
- Understand what batch metrics are best monitored (e.g. yield, batch mean or median)
- Appreciate when you need to perform a multiple factor experiment and when you need to perform a single factor experiment
Suggestion: Get into the habit of checking these learning objectives after completing each tutorial
Tutorial Exercises
1 – Getting started using PV Factory
To get a sign-on to PV Factory use this link.
PV Factory has a number of leaderboards. There are the public leaderboards (for all users of PV Factory) and there will be a set of leaderboards if you are part of a class. To join a leaderboard, you need to be invited by your class coordinator. When you are in PV Factory, first select the UNSW Screen Print Line and then go into the Office. Select the option Leaderboards, if you are part of a class with a leaderboard, at the top you should be able to select your class’s leaderboard. If you can see your group as a leaderboard option then you have successfully joined the class and are ready to go!
2 – Samples, Populations and Confidence Intervals
You can use the this link to download a set of I-V data for a batch of 20 cells processed in PV Factory. The cells were all processed using the same processing sequence and parameters. Perform the analysis below and complete Table 1:
| PARAMETER | XBatch | SBatch | Median | DF | SE | TC | CI (95%) |
| Voc | e.g., xx ± (½)CI | ||||||
| Jsc | |||||||
| FF | |||||||
| Efficiency |
- Calculate the sample mean (XBatch), standard deviation (SBatch) and standard error (SE) for each of the I-V
- Plot a frequency histogram with the cumulative frequency for each of the VOC, JSC, FF and Efficiency.
- Do the distributions of each of your I-V parameters follow a normal distribution? If not can you suggest why this may the case?
- Compute the sample median for each of the VOC, JSC, FF and Efficiency.
- Calculate the degrees of freedom (DF).
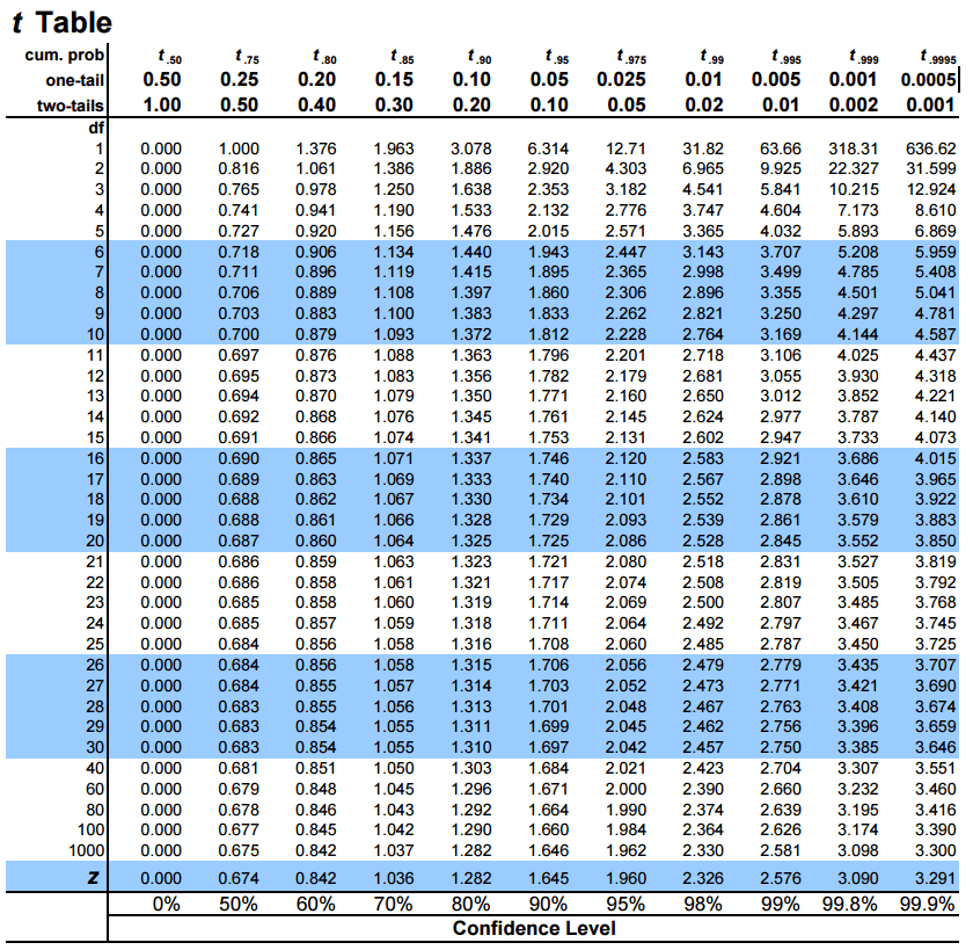
- Compute the two-tailed confidence intervals (CI) for each of the I-V parameters with 95% confidence. Use Figure 1 or use the Excel function T.INV.2T() function to obtain TC. Express your result with CIs to the correct number of significant figures.
- Is it valid to use a T-test to estimate a CI if a measured data distribution is not normal?
- From a manufacturer’s perspective what would be the most useful measure of cell efficiency to monitor: (i) the mean; or (ii) the median?
- What mechanical yield should you expect to achieve?
Table 2 – T values for One and Two sided distributions
3 – Extension exercises
- You can test whether a distribution is normally distributed by constructing a Normal Probability Plot.
- Another way in which you can show the variability in your data is to use a box plat. Unfortunately this is not a “native” graph type for Excel but you can construct box plots using stacked charts in Excel. Explore how you might use box plots to demonstrate the variability in the provided I-V